
Existing logging libraries are based on a design from the 80s and early 90s. Most of the systems at the time where developed in standalone servers where logging messages to console or file was the predominant thing to do. Logging was mostly providing debugging information and system behavioural introspection.
Most of modern systems are distributed in virtualized machines that live in the cloud. These machines could disappear any time. In this context logging on the local file system isn't useful as logs are easily lost if virtual machines are destroyed. Therefore it is common practice to use log collectors and centralized log processors. The ELK stack it has been predominant in this space for years, but there are a multitude of other commercial and open-source products.
Most of these systems have to deal with non structured data represented as formatted strings in files. The process of extracting information out of these strings is very tedious, error prone, and definitely not fun. But the question is: why did we encode these as strings in the first place? This is just because existing log frameworks, which have been redesigned in various decades follow the same structure as when systems lived on the same single server for decades.
I believe we need the break free of these anachronistic designs and use event loggers, not message loggers, which are designed for dynamic distributed systems living in cloud and using centralized log aggregators.
- Motivation for
µ/log.
I think this description is essentially correct. Existing logging libraries, especially those in the Java ecosystem, are not "fit predators" for the modern world.
I claim that we can do meaningfully better.
Whether the design I come up with at the end of this is that better solution I do not know, but if it isn't I hope it spurs someone to make whatever is.
µ/log is a Clojure library written by the author of the quote above.
Clojure is a dynamically typed functional language. Not every design choice made by µ/log will make sense for the statically typed Java, but there is bound to be a lot to pull.
A logging call in µ/log looks something like this.
(μ/log :minesweeper.event/clicked-square :was-bomb true)This first argument is the event type. It is stated best practice that the event type should have both a "namespace" and a "name". minesweeper.event and clicked-square respectively.
The rest of the arguments are key-value pairs of arbitrary data. The convention in Clojure would be for that arbitrary data to be made of "data primitives" instead of "named aggregates".
// In Java, data is often tied to a "named aggregate"
public final class Dog {
private final String name;
public Dog(String name) {
this.name = name;
}
// And how data is accessed from that aggregate
// is totally arbitrary, though conventions like
// getX can allow for heuristics.
public String retrieveName() {
return this.name;
}
};; In clojure it would be uncommon to have a named "Dog" object
(deftype Dog [name])
(μ/log :cool.dog/barked :loud true :dog (new Dog "jenny"))
;; Instead, you would have a "raw map" with data about said doggo.
(μ/log :cool.dog/barked :loud true :dog {:name "rhodie"})So while there are mechanisms to handle it, serializing user defined classes is a relatively uncommon task. Downstream consumers will generally expect values to be these "base" values - lists, maps, strings, numbers - or directly decomposable into them.
These data are then merged with a standard set of metadata about the log.
The timestamp is pretty self-explanatory, but the UUID is a bit custom.
It isn't a standard UUIDv4, but instead a construct called a "Flake" (as in snowflake, no two alike). A Flake has the following properties.
An example value looks like this: 4lIfs0B6IRjDMHo6g2Tbgrf4lzikQNXl.
I'll freely admit I don't understand the full scope of the problems this is intended to solve, but take it on faith that it's a good design and sensible alternative to UUID.randomUUID().
In addition to that standard metadata, any global or local (bound within a lexical scope) context is included.
Global context is intended to be set at the start of the program with unchanging metadata.
(μ/set-global-context! {:app-name "cool-trail-cam"})Internally this information is stored in an atom - a thin wrapper over an AtomicReference.
(defonce ^{:doc "The global logging context is used to add properties
which are valid for all subsequent log events. This is
typically set once at the beginning of the process with
information like the app-name, version, environment, the
pid and other similar info."}
global-context (atom {}))Local context is bound using the μ/with-context macro.
(μ/with-context {:request-id "685a40fd-8740-4a2f-85ae-d6a4b2c02bb0"}
(μ/log :cool.dog/barked :loud true :dog {:name "rhodie"}))By virtue of being stored and retrieved from a ThreadLocal, this context will be propagated even across function calls.
(def ^{:doc "The local context is local to the current thread,
therefore all the subsequent call to log withing the
given context will have the properties added as well. It
is typically used to add information regarding the
current processing in the current thread. For example
who is the user issuing the request and so on."}
local-context (ut/thread-local nil))All of this information merges together into a map that looks something like this.
{:mulog/event-name :cool.dog/barked,
:mulog/timestamp 613022400000,
:mulog/trace-id #mulog/flake "4lIfs0B6IRjDMHo6g2Tbgrf4lzikQNXl"
:mulog/namespace "cool.dog"
:app-name "cool-trail-cam"
:request-id "685a40fd-8740-4a2f-85ae-d6a4b2c02bb0"
:loud true
:dog {:name "rhodie"}}Then this map is "published".
The internals of how this publishing works are better documented elsewhere, but the gist of it is that the whole map is put into a ring buffer. An asynchronous process reads from that ring buffer and dumps to ring buffers. Any number of asynchronous processes then periodically read from these buffers and do the work of to printing to stdout, sending it to Cloudwatch, etc.
µ/log calls each of these asynchronous processes which handle logs a "publisher". This can be a bit confusing in terminology, but your code "publishes" logs to a ring buffer, an unnamed process forwards these logs to more ring buffers, then "publishers" take those logs and do work with them.
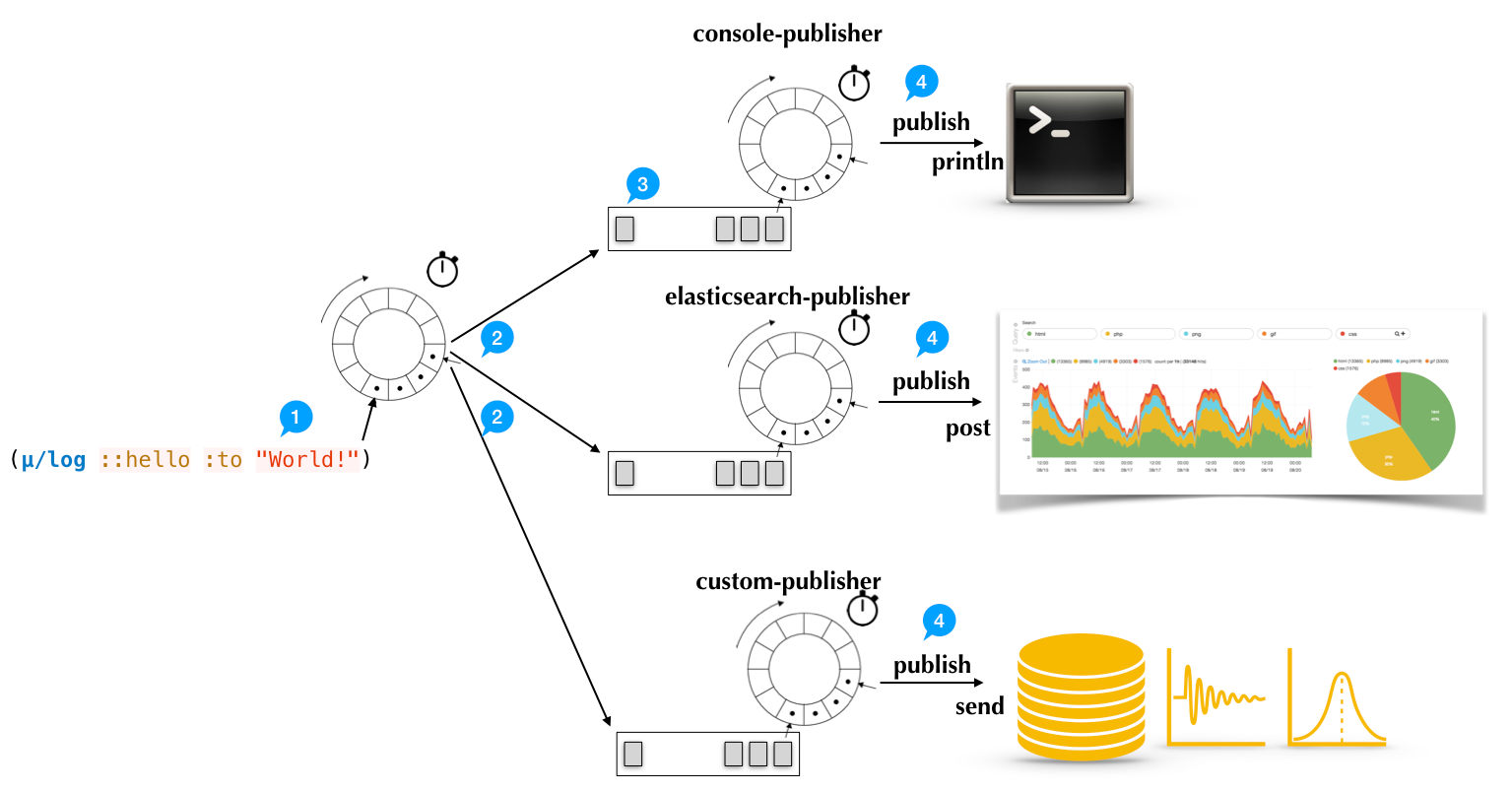
The goals of this scheme are to
(μ/start-publisher! {:type :console})
(μ/start-publisher! {:type :simple-file
:filename "/tmp/mulog/events.log"})
(μ/start-publisher!
{:type :elasticsearch
:url "http://localhost:9200/"})The final wrinkle is that in addition to logging "events" - a record of something that happened at a given point in time - µ/log lets you record "traces" - a record of a process that occurred over a span of time.
(μ/trace :cool-dog/chasing-squirrel
[:got-away "hope so"]
(chase-squirrel))Unlike a normal log this adds metadata signifying the duration of the process, whether that process terminated with an exception, and parent traces that the current trace is nested under.
{:mulog/event-name :cool-dog/chasing-squirrel,
:mulog/timestamp 609652800000,
:mulog/duration 777600000
:mulog/trace-id #mulog/flake "4lLBQ0kk-mmdCFrwI8Ravb6c8S3ddpq-"
:mulog/root-trace #mulog/flake "4lLBQ0kbx1weOm_TT5Wynok6GLBllXQC"
:mulog/outcome :ok
:mulog/namespace "cool.dog"
:app-name "cool-trail-cam"
:got-away true}
;; If it fails, outcome will be :error and the exception included.
{:mulog/event-name :cool-dog/chasing-squirrel,
:mulog/timestamp 609652800000,
:mulog/duration 777600000
:mulog/trace-id #mulog/flake "4lLBQ0kk-mmdCFrwI8Ravb6c8S3ddpq-"
:mulog/root-trace #mulog/flake "4lLBQ0kbx1weOm_TT5Wynok6GLBllXQC"
:mulog/outcome :error
:mulog/exception ...
:mulog/namespace "cool.dog"
:app-name "cool-trail-cam"
:got-away true}tracing is a Rust library with holistically similar goals to µ/log.
There is a similar Rust library named slog which deserves mention. It has been around longer and has a stable API, but tracing has better support for interacting with Rust's async ecosystem and a larger active community. To quote slog's docs.
Please check tracing and see if it is more suitable for your use-case. It seems that it is already a go-to logging/tracing solution for Rust.
My impression is that a lot of the broad strokes are the same, so I am going to focus mostly on tracing.
tracing is built on top of three core concepts, spans, events, and subscribers.
Spans are records of a "period of time" with a beginning and an end. This is a close parallel to what µ/log calls a "trace".
let span = span!(Level::INFO, "toasting toast");
let _guard = span.enter();
// when _guard is dropped, the span is closed.Semantically, this makes use of a property of Rust that doesn't exist in the JVM. When a struct in Rust is no longer in lexical scope, it is immediately "dropped." Dropping can implicitly run arbitrary code such as freeing memory, closing a socket, or - in this case - doing whatever work is needed to "close" a span.
Spans also have a new kind of metadata attached to them in the "Level." The level serves two purposes
ERROR spans or events, that is probably a sign something is afoot.TRACE spans and events might be relevant, but probably irrelevant in production.Events are records of something that happened at a single point in time. This is closest to what we would classically call a "log."
event!(Level::INFO, "toast popped in");Events interact with spans in that any events emitted while a span is active will be "nested" under that span.
let span = span!(Level::INFO, "toasting toast");
let _guard = span.enter();
event!(Level::INFO, "toast popped in");
// We know that the toast burned while toasting toast
// but does a toaster toast toast or does toast toast toast?
event!(Level::WARN, "toast burned");
// when _guard is dropped, the span is closed.Spans and events are by default sent to the "global subscriber", which is meant to be set at the start of the program.
let global_subscriber = ConsoleLoggingSubscriber::new();
tracing::subscriber::set_global_default(global_subscriber)
.expect("Failed to set");This is stored inside a static mutable variable, which is prevented from being set twice or in a race by way of a global AtomicUsize.
static GLOBAL_INIT: AtomicUsize = AtomicUsize::new(UNINITIALIZED);
const UNINITIALIZED: usize = 0;
const INITIALIZING: usize = 1;
const INITIALIZED: usize = 2;
static mut GLOBAL_DISPATCH: Option<Dispatch> = None;
// ...
pub fn set_global_default(dispatcher: Dispatch) ->
Result<(), SetGlobalDefaultError> {
if GLOBAL_INIT.compare_and_swap(
UNINITIALIZED,
INITIALIZING,
Ordering::SeqCst) == UNINITIALIZED
{
unsafe {
GLOBAL_DISPATCH = Some(dispatcher);
}
GLOBAL_INIT.store(INITIALIZED, Ordering::SeqCst);
EXISTS.store(true, Ordering::Release);
Ok(())
} else {
Err(SetGlobalDefaultError { _no_construct: () })
}
}Subscribers are notified when an event happens, when a span is entered, when a span is exited, and a few other things.
pub trait Subscriber: 'static {
fn enabled(&self, metadata: &Metadata<'_>) -> bool;
fn new_span(&self, span: &Attributes<'_>) -> Id;
fn record(&self, span: &Id, values: &Record<'_>);
fn record_follows_from(&self, span: &Id, follows: &Id);
fn event(&self, event: &Event<'_>);
fn enter(&self, span: &Id);
fn exit(&self, span: &Id);
fn register_callsite(&self, metadata: &'static Metadata<'static>)
-> Interest { ... }
fn max_level_hint(&self) -> Option<LevelFilter> { ... }
fn event_enabled(&self, event: &Event<'_>) -> bool { ... }
fn clone_span(&self, id: &Id) -> Id { ... }
fn drop_span(&self, _id: Id) { ... }
fn try_close(&self, id: Id) -> bool { ... }
fn current_span(&self) -> Current { ... }
unsafe fn downcast_raw(&self, id: TypeId) -> Option<*const ()> {
...
}
}Okay, maybe more than a few other things.
These methods are related to filtering events. Given some metadata, a subscriber can say whether they always want to be informed of an event, never want to be informed, or will need to do some runtime check to know if an event is relevant. Because of the magic of Rust, these checks can sometimes totally remove the runtime cost of recording irrelevant events.
pub trait Subscriber: 'static {
fn enabled(&self, metadata: &Metadata<'_>) -> bool;
// ...
fn register_callsite(&self, metadata: &'static Metadata<'static>)
-> Interest { ... }
fn max_level_hint(&self) -> Option<LevelFilter> { ... }
fn event_enabled(&self, event: &Event<'_>) -> bool { ... }
}These methods allow for creating and manipulating spans. This is needed because Subscribers are responsible for tracking information about spans like their start and end times.
pub trait Subscriber: 'static {
fn new_span(&self, span: &Attributes<'_>) -> Id;
fn record(&self, span: &Id, values: &Record<'_>);
fn record_follows_from(&self, span: &Id, follows: &Id);
// ...
fn clone_span(&self, id: &Id) -> Id { ... }
fn drop_span(&self, _id: Id) { ... }
fn try_close(&self, id: Id) -> bool { ... }
fn current_span(&self) -> Current { ... }
}Here be dragons.
pub trait Subscriber: 'static {
// ...
unsafe fn downcast_raw(&self, id: TypeId) -> Option<*const ()> {
...
}
}And these are the more digestible ones.
pub trait Subscriber: 'static {
// ...
fn event(&self, event: &Event<'_>);
fn enter(&self, span: &Id);
fn exit(&self, span: &Id);
// ...
}The values supported by this system are defined implicitly by a "visitor" trait, where each method on the trait corresponds to a kind of data.
pub trait Visit {
fn record_debug(&mut self, field: &Field, value: &dyn Debug);
fn record_value(&mut self, field: &Field, value: Value<'_>) { ... }
fn record_f64(&mut self, field: &Field, value: f64) { ... }
fn record_i64(&mut self, field: &Field, value: i64) { ... }
fn record_u64(&mut self, field: &Field, value: u64) { ... }
fn record_i128(&mut self, field: &Field, value: i128) { ... }
fn record_u128(&mut self, field: &Field, value: u128) { ... }
fn record_bool(&mut self, field: &Field, value: bool) { ... }
fn record_str(&mut self, field: &Field, value: &str) { ... }
fn record_error(
&mut self,
field: &Field,
value: &(dyn Error + 'static)
) { ... }
}Values can therefore be a base numeric type (f64, i64, u64, i128, u128), a boolean, a string, a Rust Error, or anything that has a Debug representation. In addition, there is support for values defined via the valuable crate, which allows for more arbitrary introspection.
This can be seen as a more "typed" version of the system in µ/log. Events are still made up of "plain data" but the rolodex of what is allowed has a more explicit structure.
Similar to the current state of things in Java, there is a large portion of the ecosystem which primarily logs text based messages, often through the log crate. To deal with this, they provide a crate which massages the text based messages into tracing events called tracing_log.
For more comprehensive coverage, I recommend perusing this RustConf talk inclusive or this blog post, both by tracing's primary maintainer.
The most popular logging facade for Java is SLF4J. Logging libraries like Logback and Log4J provide a superset or a super-dee-duperset of its functionality while acting as the implementation for any code that calls SLF4J.
Nowadays, the mechanism for a library to "act as the implementation" is to provide an implementation of org.slf4j.spi.SLF4JServiceProvider via the service loader mechanism.
Most Java developers only need to interact with this at the level of knowing that they need to add both the slf4j-api and logback-classic as dependencies to their project. I still think it is worth noting because this ability to pick a logging implementation at runtime has been crucial to SLF4J's success.
In the most common usage pattern, a private static final field is set to the result of calling LoggerFactory.getLogger(Class<?>). This gets a logger where logged messages know about the class they are logged from.
public final class Main {
private static final Logger log =
LoggerFactory.getLogger(Main.class);
public static void main(String[] args) {
log.info("Hello, world");
}
}Log messages can be plain english.
log.warn("Somebody stole my plain bagel!");Or they can contain placeholders for data to be formatted into.
log.info("I just reached level {} in Mouse Quest", 987413);With special support for logging exceptions.
log.error("Hulu gives me 5 ads in a row and I pay for it!", e);Every log is associated with a level just like tracing. This functions as metadata as usual, but can also be used to avoid making potentially expensive log calls when the associated level is not enabled.
if (log.isDebugEnabled()) {
log.debug("expensive data here {}", expensiveProcesss());
}Unlike tracing, data associated with the log is intended to be directly stuffed into the message. Despite the goal being ostensibly to produce english, pseudo-structured logs tend to be common.
log.info(
"Staring background process: batchId={}, startTime={}",
batchId,
startTime
);That being said, there is some support for attaching structured data via the "Mapped Diagnostic Context" (MDC) API.
try {
MDC.put("request_id", request_id);
log.info("This will have the request id available");
} finally {
MDC.clear();
}But that system is mechanically cumbersome to use and needs to be configured explicitly within the underlying logging implementation. People don't use it that often.
It also has no way to become compatible with the upcoming ExtentLocal API, so implementations are forever locked to using ThreadLocals.
// This try/finally structure cannot be adapted.
try {
MDC.put("something", "abc");
} finally {
MDC.clear();
}
// because ExtentLocals will only be able to be set in callbacks
static final ExtentLocal<Context> CONTEXT = new ExtentLocal<>();
ExtendLocal.where(CONTEXT, ...)
.run(() -> { /* code here */ })This is a problem, or at least potentially a problem, because ExtentLocals are designed to be considerably more efficient with a high number of threads. High numbers of threads will hopefully become the norm with Java 19+, so its worth thinking about.
And as of the very latest version there is now also an api for doing structured logging directly with KeyValuePairs and the fluent logging api.
logger.atInfo()
.addKeyValue("cat", "fred")
.addKeyValue("snuggles", true)
.log("I love this cat.");I'd say the jury is out on whether this actually will lead to many folks doing any degree of structured logging in practice, but it is certainly a welcome addition.
Since Java 9, there has actually been a logger bundled which functions somewhat similarly to SLF4J. The major points of distinction are that there are no explicit info, warn, error, etc. methods for logging at a particular level, there is direct support for localization via a ResourceBundle, and there is no parallel to MDC.
public interface Logger {
String getName();
boolean isLoggable(Level level);
default void log(Level level, String msg) {
// ...
}
default void log(Level level, Supplier<String> msgSupplier) {
// ...
}
default void log(Level level, Object obj) {
// ...
}
default void log(Level level, String msg, Throwable thrown) {
// ...
}
default void log(Level level, Supplier<String> msgSupplier,
Throwable thrown) {
// ...
}
default void log(Level level, String format, Object... params) {
// ...
}
void log(Level level, ResourceBundle bundle, String msg,
Throwable thrown);
void log(Level level, ResourceBundle bundle, String format,
Object... params);
}OpenTelemetry is definitely worth a mention, if not solely for the voice in the back of my head telling me that I am just making that but poorly and less well-thought-out.
OpenTelemetry defines a set of language agnostic standards for how "observability data" should be recorded within an application and how it should be communicated and propagated to the rest of the system.
I am going to make the controversial, yet brave decision to not explain much of it here. The documentation is far more thorough than I can be and enough of the concepts overlap that explaining the distinctions between what I'm writing and what the OpenTelemetry automatic and manual instrumentation libraries provide would double the size of this post.
My hope is that what comes out of this whole thought experiment could potentially serve as a frontend to its manual instrumentation component, but I'm not going to make that a focus.
It is overall pretty cool though. If I had to give anything concretely negative about it, it would be that my first experience using the automatic instrumentation library was it causing the startup time for a few services to exceed our health check grace period. That sucked.
As of right now though, luckily for me, OpenTelemetry doesn't provide a stable way to emit structured logs.
Going in to this I want something which
So first task on the docket is to make an interface for our logger.
/**
* A logger.
*/
public interface Logger {
/**
* Logs the log.
*
* @param log The log to log.
*/
void log(Log log);
}Nailed it.
Now, there is actually some deeper reasoning here. In µ/log's design all logs are juggled between ring buffers and passed between different consumers. Doing that is a lot easier when we make a Log a concrete thing that can be passed around.
µ/log also gets away with no equivalent of tracing's span_enter and span_exit. This leads me to believe (hand wavingly) that if you aren't in the pursuit of true zero cost like rust is, it is fine to only perform actions on span_exit and have the logic usually covered by span_enter (starting the timer, assigning an id, etc.) be handled in another way.
So a single log method it is. Default methods can and will be added to make a more pleasant API, but that's the start.
Now as to what constitutes a Log, at this stage I haven't laid out the full picture, so it's hard to talk about. I do think, however, that delineating Events and Spans like tracing would be a good idea.
µ/log doesn't need to care about this because it is Clojure. In a dynamic language it is an expected sort of pattern to say "if this map has :mulog/root-trace and :mulog/duration it represents a span." You can see that exact example in its zipkin publisher
The best tool I know of for directly representing this is sealed interfaces.
public sealed interface Log {
record Event() implements Log {}
record Span() implements Log {}
}You can read this as "a Log is either an Event or a Span." Any information common to the two cases will be added to the interface as we move along.
tracing has log levels and µ/log does not.
The way I see it, there are ways to think about levels.
I bounced back and forth for a bit, but Goal #2 tips the scales. Java programmers are used to levels, let them have levels.
enum Level {
TRACE,
DEBUG,
INFO,
WARN,
ERROR
}If there are situations that arise in practice where no log level is appropriate a dedicated "unspecified" level could make sense, but I'm putting that in my back pocket for now.
enum Level {
UNSPECIFIED,
TRACE,
DEBUG,
INFO,
WARN,
ERROR
}If not for Goal #2 there is no intrinsic reason these need to be the log levels either, but c'est la vie.
enum Level {
DEVELOPMENT_ONLY,
FIX_DURING_WORK_HOURS,
WAKE_ME_UP_IN_THE_MIDDLE_OF_THE_NIGHT
}I am also choosing to nest this enum inside the Log interface.
public sealed interface Log {
record Event() implements Log {}
record Span() implements Log {}
enum Level {
TRACE,
DEBUG,
INFO,
WARN,
ERROR
}
}This is a stylistic choice more than anything, but I like being able to refer to Log.Level as such. Not only does the pattern give one place for discovery - just type Log. in your IDE to see the full set of log related types - it can save me from having to add Log as a prefix to class names.
Both Events and Spans should have log levels, so that is represented like so.
public sealed interface Log {
Level level();
record Event(
@Override Level level
) implements Log {}
record Span(
@Override Level level
) implements Log {}
enum Level {
TRACE,
DEBUG,
INFO,
WARN,
ERROR
}
}I think µ/log had the right idea. Most logs should have both a "namespace" and a "name" component as their identifier. It is a pattern I think is pretty common in systems meant to take in structured data.
One example: Cloudwatch wants both a "source" and "detail-type" for their events.
{
"version": "0",
"id": "6a7e8feb-b491-4cf7-a9f1-bf3703467718",
"detail-type": "EC2 Instance State-change Notification",
"source": "aws.ec2",
"account": "111122223333",
"time": "2017-12-22T18:43:48Z",
"region": "us-west-1",
"resources": [
"arn:aws:ec2:us-west-1:123456789012:instance/ i-1234567890abcdef0"
],
"detail": {
"instance-id": " i-1234567890abcdef0",
"state": "terminated"
}
}It also gives a convenient analogue to the "class doing the logging" and "log message" that programmers are already used to. I'll call the pair of these two pieces the log's "category."
public sealed interface Log {
// ...
record Category(String namespace, String name) {
}
}I can't imagine Events having categories but Spans not having them so they both get them.
public sealed interface Log {
Level level();
Category category();
record Event(
@Override Level level,
@Override Category category
) implements Log {}
record Span(
@Override Level level,
@Override Category category
) implements Log {}
// ...
record Category(String namespace, String name) {
}
}At this point we can start to sketch out what logging would look like.
Logger log = ...;
log.log(
new Log.Event(
Log.Level.INFO,
new Log.Category("some.Thing", "thing-happened")
)
);Hideous.
So clearly some helper methods are in order.
To start, one helper method for logging an event. Spans can come later.
/**
* A logger.
*/
public interface Logger {
/**
* Logs the log.
*
* @param log The log to log.
*/
void log(Log log);
default void event(
Log.Level level,
Log.Category category
) {
log(new Log.Event(level, category));
}
}So now the verbose new Log.Event call is not needed.
Logger log = ...;
log.event(
Log.Level.INFO,
new Log.Category("some.Thing", "thing-happened")
);Next, it is common to have a dedicated method for each log level.
/**
* A logger.
*/
public interface Logger {
/**
* Logs the log.
*
* @param log The log to log.
*/
void log(Log log);
default void event(
Log.Level level,
Log.Category category
) {
log(new Log.Event(level, category));
}
default void trace(
Log.Category category
) {
event(Log.Level.TRACE, category);
}
default void debug(
Log.Category category
) {
event(Log.Level.DEBUG, category);
}
default void info(
Log.Category category
) {
event(Log.Level.INFO, category);
}
default void warn(
Log.Category category
) {
event(Log.Level.WARN, category);
}
default void error(
Log.Category category
) {
event(Log.Level.ERROR, category);
}
}Logger log = ...;
log.info(new Log.Category("some.Thing", "thing-happened"));This is better still, but the new Log.Category still feels like a lot to ask of folks on every single call.
For most applications, the namespace component of logs emitted from any particular class is likely to stay constant. It is probably going to be the class name.
As such, I think that there should be two types. Logger and Logger.Namespaced. Logger will let folks log while specifying the full Log.Category and Logger.Namespaced will have the namespace part of the category pre-filled.
/**
* A logger.
*/
public interface Logger {
/**
* Logs the log.
*
* @param log The log to log.
*/
void log(Log log);
default void event(
Log.Level level,
Log.Category category
) {
log(new Log.Event(level, category));
}
// ...
default Namespaced namespaced(String namespace) {
return new NamespacedLogger(namespace, this);
}
interface Namespaced {
void event(Log.Level level, String name);
default void trace(
String name
) {
event(Log.Level.TRACE, name);
}
default void debug(
String name
) {
event(Log.Level.DEBUG, name);
}
default void info(
String name
) {
event(Log.Level.INFO, name);
}
default void warn(
String name
) {
event(Log.Level.WARN, name);
}
default void error(
String name
) {
event(Log.Level.ERROR, name);
}
}
}// The implementation is trivial
record NamespacedLogger(String namespace, Logger logger)
implements Logger.Namespaced {
public void event(Log.Level level, String name) {
logger.event(
level,
new Log.Category(this.namespace, name)
);
}
}Before adding support for spans to the logger, we need to take a minor detour. The key difference between an Event and a Span is that an Event happens at a singular point in time while a Span takes place over a span of time.
This could be represented directly, by having Events track when they happened and having Spans track their start time and how long they lasted.
public sealed interface Log {
Level level();
Category category();
record Event(
@Override Level level,
@Override Category category,
Instant happenedAt
) implements Log {}
record Span(
@Override Level level,
@Override Category category,
Instant startedAt,
Duration lasted
) implements Log {}
// ...
}Personally though, I find it more interesting to unify the concepts a little. Every log occurs at some time that is either a singular point of time or a span of time.
public sealed interface Log {
// ...
sealed interface Occurrence {
record PointInTime(
java.time.Instant happenedAt
) implements Occurrence {
}
record SpanOfTime(
java.time.Instant startedAt,
java.time.Duration lasted
) implements Occurrence {
}
}
}This lets us put Occurrence on the Log interface directly, while still having Event and Span only have the data they want.
public sealed interface Log {
Occurrence occurrence();
Level level();
Category category();
record Event(
@Override Occurrence.PointInTime occurrence,
@Override Level level,
@Override Category category
) implements Log {}
record Span(
@Override Occurrence.SpanOfTime occurrence,
@Override Level level,
@Override Category category
) implements Log {}
// ...
sealed interface Occurrence {
record PointInTime(
java.time.Instant happenedAt
) implements Occurrence {
}
record SpanOfTime(
java.time.Instant startedAt,
java.time.Duration lasted
) implements Occurrence {
}
}
}For Events, we can make it a bit easier by adding a constructor which sets the occurrence to the current point in time.
public sealed interface Log {
Occurrence occurrence();
Level level();
Category category();
record Event(
@Override Occurrence.PointInTime occurrence,
@Override Level level,
@Override Category category
) implements Log {
public Event(
Level level,
Category category
) {
this(Instant.now(), level, category);
}
}
record Span(
@Override Occurrence.SpanOfTime occurrence,
@Override Level level,
@Override Category category
) implements Log {}
// ...
sealed interface Occurrence {
record PointInTime(
java.time.Instant happenedAt
) implements Occurrence {
}
record SpanOfTime(
java.time.Instant startedAt,
java.time.Duration lasted
) implements Occurrence {
}
}
}For Spans that doesn't make quite as much sense, so auto-timing logic will probably end up being in the logger.
There are two general strategies that would work for adding Spans to the Logger and Logger.Namespaced interfaces.
The first is for a method to return something closeable. When that something is closed, the span is finished.
public interface Logger {
void log(Log log);
// ...
interface SpanHandle extends AutoCloseable {
void close();
}
default SpanHandle span(
Log.Level level,
Log.Category category
) {
var start = Instant.now();
return () -> {
var end = Instant.now();
log(
new Log.Span(
new Occurance.SpanOfTime(
start,
Duration.between(start, end)
)
),
level,
category
);
};
}
// ...
}try (var handle = log.span(
Log.Level.INFO,
new Log.Category("something", "happened"))) {
// Span open here
System.out.println("I am in the span!");
}
// Closed when you exitThis is convenient to use with the try-with-resources syntax and has the nice benefit of playing well with checked exceptions.
By that I mean, if the code within the span wants to throw a checked exception upwards a level or to be handled in a certain way, it is trivial to propagate that exception up.
void func() throws IOException, SQLException {
try (var handle = log.span(
Log.Level.INFO,
new Log.Category("something", "happened"))) {
codeThatThrowsIOExceptionOrSqlException();
}
// Closed when you exit
}The other way is to directly take some code to run as a callback.
public interface Logger {
void log(Log log);
// ...
default <T> T span(
Log.Level level,
Log.Category category,
Supplier<T> code
) {
var start = Instant.now();
try {
return code.get();
} catch (Throwable t) {
var end = Instant.now();
log(
new Log.Span(
new Occurance.SpanOfTime(
start,
Duration.between(start, end)
)
),
level,
category
);
}
}
default void span(
Log.Level level,
Log.Category category,
Runnable code
) {
span(level, category, () -> {
code.run();
return null;
});
}
// ...
}This has some major downsides - for one, we now can't do things like return early from a function within a span.
void func() {
int x = 8;
log.span(
Log.Level.INFO,
new Log.Category("space", "hit-debris"),
() -> {
if (x == 8) {
// Can only return directly from this lambda,
// not the whole method.
return;
}
System.out.println("Inside the span!");
}
);
System.out.println("Will get here");
}And we also cannot automatically handle checked exceptions in the general case.
Like, hypothetically the callback interface could look like this.
interface SpanCallback<E extends Throwable> {
void run() throws E;
}Which would allow us to write code which throws one kind of checked exception.
void func() throws IOException {
// Correctly throws IOException
log.span(
Log.Level.INFO,
new Log.Category("space", "hit-debris"),
() -> {
throw new IOException();
}
);
}But if code needed to throw multiple disjoint kinds of exceptions, that would be a problem since the throws E needs to resolve to a single type.
So if the code wrapped in the span throws both IOException and SQLException, the only common type would be Exception.
// Would want this to be throws IOException, SQLException...
void func() throws Exception {
log.span(
Log.Level.INFO,
new Log.Category("space", "hit-debris"),
() -> {
if (Math.random() > 0.5) {
throw new IOException();
}
else {
throw new SQLException();
}
}
);
}There are some solutions depending on sensibilities, but none are perfect.
RuntimeException subclassEven given these issues, I think the callback system is the better of the two. ExtentLocals basically mandate it and, as a tiny spoiler, Spans are going to need to propagate context to nested logs. It also isn't possible to mess up. try-with-resources is good and IDEs will warn if you don't close a returned auto-closeable, but there are still some cursed situations that can arise if you do not.
So with that settled both Logger and Logger.Namespaced are due their full complement of span methods for each log level.
public interface Logger {
void log(Log log);
// ...
default <T> T span(
Log.Level level,
Log.Category category,
Supplier<T> code
) {
// ...
}
default void span(
Log.Level level,
Log.Category category,
Runnable code
) {
// ...
}
// ...
default <T> T infoSpan(
Log.Category category,
Supplier<T> code
) {
return span(Log.Level.INFO, category, code);
}
default void infoSpan(
Log.Category category,
Runnable code
) {
span(Log.Level.INFO, category, code);
}
default <T> T warnSpan(
Log.Category category,
Supplier<T> code
) {
return span(Log.Level.WARN, category, code);
}
default void warnSpan(
Log.Category category,
Runnable code
) {
span(Log.Level.WARN, category, code);
}
// ...
interface Namepaced {
// ...
<T> T span(
Log.Level level,
String name,
Supplier<T> code
);
default void span(
Log.Level level,
String name,
Runnable code
) {
return span(level, name, () -> {
code.run();
return null;
});
}
// ...
default <T> T infoSpan(
String name,
Supplier<T> code
) {
return span(Log.Level.INFO, name, code);
}
default void infoSpan(
String name,
Runnable code
) {
span(Log.Level.INFO, name, code);
}
default <T> T warnSpan(
String name,
Supplier<T> code
) {
return span(Log.Level.WARN, name, code);
}
default void warnSpan(
String name,
Runnable code
) {
span(Log.Level.WARN, name, code);
}
// ...
}
}To be useful, logs often need to carry some dynamic information. What user is making the request? What is the database record that is about to be altered?
These are the "log entries." The representation for this seems to be pretty universally key-value pairs, so that is what I am going with.
sealed interface Log {
// ...
record Entry(String key, Value value) {}
}It follows that logs will get some list of log entries.
public sealed interface Log {
Occurrence occurrence();
Level level();
Category category();
List<Entry> entries();
record Event(
@Override Occurrence.PointInTime occurrence,
@Override Level level,
@Override Category category,
@Override List<Entry> entries
) implements Log {
public Event(
Level level,
Category category
) {
this(
new Occurrence.PointInTime(Instant.now()),
level,
category
);
}
}
record Span(
@Override Occurrence.SpanOfTime occurrence,
@Override Level level,
@Override Category category,
@Override List<Entry> entries
) implements Log {}
// ...
record Entry(String key, Value value) {}
}µ/log merges its log entries immediately into a map, but I don't think this is necessary.
For one, we are going to be adding semantics to Log.Entry that don't exist in Map.Entry like requiring that the key and value be non-null.
public sealed interface Log {
// ...
record Entry(String key, Value value) {
public Entry {
Objects.requireNonNull(
key,
"key must not be null"
);
Objects.requireNonNull(
value,
"value must not be null"
);
}
}
}Also, the most common operation that is going to be performed is iterating over the full list of entries to build some JSON or similar. All the pieces of the logs that have semantic significance - like the level or when they occurred - have dedicated methods and places in the objects for them.
µ/log is also slightly special in that the keys in its maps generally wouldn't be Strings. It is idiomatic in clojure to use keywords and keywords have the distinction of having a precomputed hash code. If the internal representation were a Map<String, Value> then there would be a constant and probably pointless cost for doing that hashing.
Both Logger and Logger.Namespaced need to be updated as well.
interface Logger {
// ...
default void info(
Log.Category category,
List<Log.Entry> entries
) {
// ...
}
default <T> T infoSpan(
Log.Category category,
List<Log.Entry> entries,
Supplier<T> code
) {
// ...
}
// ...
interface Namespaced {
// ...
default void info(
String name,
List<Log.Entry> entries
) {
// ...
}
default <T> T infoSpan(
String name,
List<Log.Entry> entries,
Supplier<T> code
) {
// ...
}
// ...
}
}Using List.of() to manually make lists is a bit tedious and this parameter does often come at the end of the arguments list, so a varargs overload feels a good idea.
interface Logger {
// ...
interface Namespaced {
// ...
default void info(
String name,
List<Log.Entry> entries
) {
// ...
}
default void info(
String name,
Log.Entry... entries
) {
info(name, List.of(entries));
}
// ...
}
}Syntactically we can stop there, but if you take a gander at the docs for List.of() you will see everything up to a ten argument overload. This is pretty plainly to avoid allocating the array for varargs, so it might make sense to do that for this API too.
Five log levels plus one base event method in Logger and also in Logger.Namespaced. If I gave each all ten argument overloads to match the overloads of List.of() that would be extra 120 methods plus carpal tunnel. For the hypothetical performance of something no one is using yet.
I'm not going to do that.
Which just leaves open the question, what exactly is a Value?
Taking a page from tracing, I am going to restrict what is allowed as a Value.
So long as strings, numbers, booleans, lists, and maps are represented anything is probably acceptable, but I am going to be a bit liberal with what is allowed.
A good place to start might be to put my foot down and say that booleans are allowed.
sealed interface Value {
// ...
record Boolean(boolean value) implements Value {
}
// ...
}Any of the primitive numeric types are okay.
sealed interface Value {
// ...
record Byte(byte value) implements Value {
}
record Character(char value) implements Value {
}
record Short(short value) implements Value {
}
record Integer(int value) implements Value {
}
record Long(long value) implements Value {
}
record Float(float value) implements Value {
}
record Double(double value) implements Value {
}
// ...
}And Strings seem pretty cool too.
sealed interface Value {
// ...
record String(java.lang.String value) implements Value {
// ...
public String {
Objects.requireNonNull(value, "value must not be null");
}
}
// ...
}UUIDs are relatively common to come across and are immutable and pretty trivially translatable to a string.
sealed interface Value {
// ...
record UUID(java.util.UUID value) implements Value {
public UUID {
Objects.requireNonNull(value, "value must not be null");
}
}
// ...
}URIs (not URLs!) are equally simple and come up quite a bit when making web services.
sealed interface Value {
// ...
record URI(java.net.URI value) implements Value {
public URI {
Objects.requireNonNull(value, "value must not be null");
}
}
// ...
}The types in java.time are pretty crucial.
sealed interface Value {
// ...
record Instant(java.time.Instant value) implements Value {
public Instant {
Objects.requireNonNull(value, "value must not be null");
}
}
record LocalDateTime(java.time.LocalDateTime value) implements Value {
public LocalDateTime {
Objects.requireNonNull(value, "value must not be null");
}
}
record LocalDate(java.time.LocalDate value) implements Value {
public LocalDate {
Objects.requireNonNull(value, "value must not be null");
}
}
record LocalTime(java.time.LocalTime value) implements Value {
public LocalTime {
Objects.requireNonNull(value, "value must not be null");
}
}
record Duration(java.time.Duration value) implements Value {
public Duration {
Objects.requireNonNull(value, "value must not be null");
}
}
// ...
}And Exceptions must be in the top 10 things to want to log.
sealed interface Value {
// ...
record Throwable(java.lang.Throwable value) implements Value {
public Throwable {
Objects.requireNonNull(value, "value must not be null");
}
}
// ...
}Logging Lists is one of the things that we need to support to keep parity with µ/log and tracing
sealed interface Value {
// ...
record List(java.util.List<Value> value) implements Value {
}
// ...
}At which point, we need to talk about null.
In all the cases so far, I've added an Objects.requireNonNull to the canonical constructor for each of these cases. To me this tracks because it wouldn't make much sense to have both a "String" and an "Instant" with null values allowed.
// Should this be true or false?
// If it should be true that will require some wacky equals method.
Objects.equals(
new Log.Entry.Value.String(null),
new Log.Entry.Value.Instant(null),
)The problem is, people end up with null values pretty much constantly. Logging that you are about to perform some operation on an entity and that entity is unexpectedly null is unbelievably common.
// Sorry, we crashed because of a log!
new Log.Entry.Value.String(s);To remedy this, I could add constructor functions to Log.Entry.Value which automatically handle null values.
sealed interface Value {
// ...
static Value.String of(java.lang.String value) {
if (value == null) {
return null;
}
else {
return new String(value);
}
}
record String(java.lang.String value) implements Value {
// ...
public String {
Objects.requireNonNull(value, "value must not be null");
}
}
// ...
}For the primitive types it will be a little pointless, but it can help avoid errors with their wrappers.
sealed interface Value {
// ...
static Value.Boolean of(boolean value) {
return new Boolean(value);
}
static Value.Boolean of(java.lang.Boolean value) {
if (value == null) {
return null;
}
else {
return new Boolean(value);
}
}
record Boolean(boolean value) implements Value {
}
// ...
}But with lists, there is another foot gun we have just loaded. Lists made with List.of do not support null elements, so it is more than likely folks will end up with seemingly okay code and an inexplicable crash.
// If null, will still crash!
Log.Entry.Value.of(List.of(
Log.Entry.Value.of(someString)
))So to sidestep this, we need to make our own null. It feels contrived, I know.
sealed interface Value {
enum Null implements Value {
INSTANCE;
@Override
public java.lang.String toString() {
return "Null";
}
}
}Then for all the constructor functions, this becomes the fallback.
sealed interface Value {
// ...
static Value of(java.lang.String value) {
if (value == null) {
return Null.INSTANCE;
}
else {
return new String(value);
}
}
enum Null implements Value {
INSTANCE;
@Override
public java.lang.String toString() {
return "Null";
}
}
record String(java.lang.String value) implements Value {
// ...
public String {
Objects.requireNonNull(value, "value must not be null");
}
}
// ...
}Which solves our current issue fairly neatly.
String s1 = "abc";
String s2 = null;
// Our "Null" isn't "null", so all is well.
Log.Entry.Value.of(List.of(
Log.Entry.Value.of(s1),
Log.Entry.Value.of(s2)
))The remaining kinds of data to consider are maps and sets. Both would have had the same issues with null and their convenient constructor functions in Map.of() and Set.of() so it is good to have that resolved.
sealed interface Value {
// ...
record Map(java.util.Map<java.lang.String, Value> value)
implements Value {
public Map(java.util.Map<java.lang.String, Value> value) {
Objects.requireNonNull(value, "value must not be null");
this.value = value.entrySet()
.stream()
.collect(Collectors.toUnmodifiableMap(
java.util.Map.Entry::getKey,
entry -> entry.getValue() == null
? Null.INSTANCE
: entry.getValue()
));
}
}
record Set(java.util.Set<Value> value) implements Value {
public Set(java.util.Set<Value> value) {
Objects.requireNonNull(value, "value must not be null");
this.value = value.stream()
.map(v -> v == null ? Null.INSTANCE : v)
.collect(Collectors.toUnmodifiableSet());
}
}
}For Maps there is no intrinsic reason it has to be this way, but I chose to restrict the keys to be Strings. This is both more convenient for eventual serialization to JSON and avoids issues like having two keys which would serialize to the same form if string-ified.
// This would be annoying to handle in JSON
Log.Entry.Value.of(Map.of(
Log.Entry.Value.of(123), Log.Entry.Value.of("abc"),
Log.Entry.Value.of("123"), Log.Entry.Value.of("def"),
))Now for the last value kind, I promise. Occasionally producing the value for a log might be either expensive, intrinsically fallible, or both - like fetching a value from a remote server. For this, we want to provide a way to lazily compute a value.
I took the implementation of this from a combo of vavr's Lazy and Clojure's delay.
sealed interface Value {
// ...
final class Lazy implements Value {
// Implementation based off of clojure's Delay + vavr's Lazy
private volatile Supplier<? extends Value> supplier;
private Value value;
public Lazy(Supplier<? extends Value> supplier) {
Objects.requireNonNull(
supplier,
"supplier must not be null"
);
this.supplier = supplier;
this.value = null;
}
public Value value() {
if (supplier != null) {
synchronized (this) {
final var s = supplier;
if (s != null) {
try {
this.value = Objects.requireNonNullElse(
s.get(),
Null.INSTANCE
);
} catch (java.lang.Throwable throwable) {
this.value = new Throwable(throwable);
}
this.supplier = null;
}
}
}
return this.value;
}
@Override
public java.lang.String toString() {
if (supplier != null) {
return "Lazy[pending]";
} else {
return "Lazy[realized: value=" + value() + "]";
}
}
}
}And this gets its own ofLazy factory functions of course.
sealed interface Value {
// ...
static Value ofLazy(Supplier<Value> valueSupplier) {
return new Value.Lazy(valueSupplier);
}
static <T> Value ofLazy(T value, Function<T, Value> toValue) {
return new Value.Lazy(() -> {
var v = toValue.apply(value);
return v == null ? Value.Null.INSTANCE : v;
});
}
// ...
}Now to make a log it will look like this.
log.info("dog-barked", new Log.Entry(
"name",
Log.Entry.Value.of("gunny")
));Which is still a bit too verbose, so for all of those Value constructor functions I will add a matching one in Log.Entry.
log.info("dog-barked", Log.Entry.of("name", "gunny"));Which is finally terse enough that I could believe your average Jane or Joe writing it.
Now a bit of a roundup, I am giving logs the Flake from µ/log. I actually copied the class exactly as written.
public sealed interface Log {
Flake flake();
Occurrence occurrence();
Level level();
Category category();
List<Entry> entries();
record Event(
@Override Flake flake,
@Override Occurrence.PointInTime occurrence,
@Override Level level,
@Override Category category,
@Override List<Entry> entries
) implements Log {
public Event(
Level level,
Category category
) {
this(
Flake.create(),
new Occurrence.PointInTime(Instant.now()),
level,
category
);
}
}
record Span(
@Override Flake flake,
@Override Occurrence.SpanOfTime occurrence,
@Override Level level,
@Override Category category,
@Override List<Entry> entries
) implements Log {}
// ...
}Apparently, getting the current thread is basically free and since the ultimate goal is to allow sending logs around to different threads than when they originated gathering that for metadata feels appropriate.
public sealed interface Log {
Thread thread();
Flake flake();
Occurrence occurrence();
Level level();
Category category();
List<Entry> entries();
record Event(
@Override Thread thread,
@Override Flake flake,
@Override Occurrence.PointInTime occurrence,
@Override Level level,
@Override Category category,
@Override List<Entry> entries
) implements Log {
public Event(
Level level,
Category category
) {
this(
Thread.currentThread(),
Flake.create(),
new Occurrence.PointInTime(Instant.now()),
level,
category
);
}
}
record Span(
@Override Thread thread,
@Override Flake flake,
@Override Occurrence.SpanOfTime occurrence,
@Override Level level,
@Override Category category,
@Override List<Entry> entries
) implements Log {}
// ...
}When a span finishes, µ/log records whether that span threw an exception and if so what the exception was. This is very doable, we just need to make sure to catch and re-throw anything thrown when performing work a span.
sealed interface Log {
record Span(
@Override Thread thread,
@Override Flake flake,
Outcome outcome,
@Override Occurrence.SpanOfTime occurrence,
@Override Level level,
@Override Category category,
@Override List<Entry> entries) implements Log {
public sealed interface Outcome {
enum Ok implements Outcome {
INSTANCE;
@Override
public String toString() {
return "Ok";
}
}
record Error(Throwable throwable) implements Outcome {
}
}
}
}If it weren't for this, Spans and Events could probably be a single class. Unfortunately there isn't a neat value to put for an Outcome in an Event.
The last thing to worry about is context. We need some mechanism for context to propagate from span to span and across method call boundaries and we need to define what exactly is allowed to be present in context.
The easiest to consider is global context. All we need is some Log.Entrys which will be included in every log.
sealed interface Log {
sealed interface Context {
record Global(List<Entry> entries) implements Context {
}
}
}I don't see any reason to be as strict as tracing is when it comes to setting global context more than once, so using µ/log's storage strategy of an AtomicReference is likely good enough.
// Separate, internal, class to avoid exposing
class Globals {
static final AtomicReference<Log.Context.Global> GLOBAL_CONTEXT =
new AtomicReference<>(new Log.Context.Global(List.of()));
}And at any point it will be "safe" - if maybe leading to strange semantics - to set this context.
sealed interface Log {
// ...
static void setGlobalContext(List<Entry> entries) {
GLOBAL_CONTEXT.set(new Context.Global(entries));
}
// ...
}There are then two other kinds of "child" context. The first is "plain" context which is intended to just carry log entries down. The second is "span" context which doesn't carry entries but instead metadata about the current span.
sealed interface Log {
sealed interface Context {
record Global(List<Entry> entries) implements Context {
}
sealed interface Child extends Context {
Context parent();
record Plain(
List<Entry> entries,
@Override Context parent
) implements Child {
}
record Span(
Thread thread,
Instant startedAt,
Flake spanId,
@Override Context parent
) implements Child {
}
}
}
}Both Plain and Span child contexts have a field linking to their parent context. This makes this a strange and wonderful kind of linked list.
To access the immediate parent or the root span, you can just crawl the linked list. This means that unlike µ/log we don't need to explicitly pass down a :mulog/root-trace or :mulog/parent-trace. We just have to accept linked lists with all their flaws.
sealed interface Log {
sealed interface Context {
Optional<Child.Span> parentSpan();
default Optional<Child.Span> rootSpan() {
return this.parentSpan()
.map(parent -> parent.rootSpan().orElse(parent));
}
record Global(List<Entry> entries) implements Context {
@Override
public Optional<Child.Span> parentSpan() {
return Optional.empty();
}
}
sealed interface Child extends Context {
Context parent();
@Override
default Optional<Span> parentSpan() {
var parent = parent();
if (parent instanceof Span parentSpan) {
return Optional.of(parentSpan);
}
else {
return parent.parentSpan();
}
}
record Plain(
List<Entry> entries,
@Override Context parent
) implements Child {
}
record Span(
Thread thread,
Instant startedAt,
Flake spanId,
@Override Context parent
) implements Child {
}
}
}
}Now to propagate this non-global context a ThreadLocal will be used. Yes, I've mentioned many times how I want this design to be forward compatible with ExtentLocals, but getting those early access builds is a bit hard, and I don't want to lock people who want to toy with this API today to have to figure that out.
class Globals {
static final AtomicReference<Log.Context.Global> GLOBAL_CONTEXT =
new AtomicReference<>(new Log.Context.Global(List.of()));
/*
* This should be an extent local when it is possible to be so.
*/
static final ThreadLocal<Log.Context.Child> LOCAL_CONTEXT =
new ThreadLocal<>();
}Since the local context will contain a pointer to the global context that was established when it was formed, to get the current context we just need to check if there is a currently bound local context and if so use it. If not, we take from the global context.
sealed interface Log {
sealed interface Context {
static Context current() {
var localContext = LOCAL_CONTEXT.get();
return localContext == null
? GLOBAL_CONTEXT.get()
: localContext;
}
// ...
}
}And every log will have some attached context.
public sealed interface Log {
Context context();
Thread thread();
Flake flake();
Occurrence occurrence();
Level level();
Category category();
List<Entry> entries();
record Event(
@Override Context context,
@Override Thread thread,
@Override Flake flake,
@Override Occurrence.PointInTime occurrence,
@Override Level level,
@Override Category category,
@Override List<Entry> entries
) implements Log {
public Event(
Level level,
Category category
) {
this(
Context.current(),
Thread.currentThread(),
Flake.create(),
new Occurrence.PointInTime(Instant.now()),
level,
category
);
}
}
record Span(
@Override Context context,
@Override Thread thread,
@Override Flake flake,
Outcome outcome,
@Override Occurrence.SpanOfTime occurrence,
@Override Level level,
@Override Category category,
@Override List<Entry> entries
) implements Log {
public Event(
Outcome outcome,
Occurrence.SpanOfTime occurrence,
Level level,
Category category,
List<Entry> entries
) {
this(
Context.current(),
Thread.currentThread(),
Flake.create(),
outcome
occurrence,
level,
category
);
}
}
// ...
}So to add some log entries to every log made in a scope, we just need to set and unset the thread local.
sealed interface Log {
// ...
static <T> T withContext(List<Entry> entries, Supplier<T> code) {
var localContext = LOCAL_CONTEXT.get();
try {
LOCAL_CONTEXT.set(new Context.Child.Plain(
entries,
localContext == null
? GLOBAL_CONTEXT.get()
: localContext
));
return code.get();
} finally {
LOCAL_CONTEXT.set(localContext);
}
}
static void withContext(List<Entry> entries, Runnable code) {
withContext(
entries,
() -> {
code.run();
return null;
});
}
// ...
}Log.withContext(
List.of(Log.Entry.of("request-id", "abc")),
() -> {
log.info("has-request-id!");
}
)And the strategy is very similar for propagating spans, with the difference that log entries are not propagated just metadata.
interface Logger {
// ...
default <T> T span(
Log.Level level,
Log.Category category,
List<Log.Entry> entries,
Supplier<T> code
) {
Log.Span.Outcome outcome = Log.Span.Outcome.Ok.INSTANCE;
var start = Instant.now();
var localContext = LOCAL_CONTEXT.get();
try {
LOCAL_CONTEXT.set(new Log.Context.Child.Span(
Thread.currentThread(),
start,
Flake.create(),
localContext == null
? GLOBAL_CONTEXT.get()
: localContext
));
return code.get();
} catch (Throwable t) {
outcome = new Log.Span.Outcome.Error(t);
throw t;
} finally {
LOCAL_CONTEXT.set(localContext);
var end = Instant.now();
var duration = Duration.between(start, end);
var occurrence = new Log.Occurrence.SpanOfTime(
start,
duration
);
log(new Log.Span(
outcome,
occurrence,
level,
category,
entries
));
}
}
// ...
}Now putting it all together.
Log.setGlobalContext(List.of(
Log.Entry.of(
"os.name",
System.getProperty("os.name")
));
// ...
log.infoSpan(
"handling-request",
() -> {
Log.withContext(
List.of(Log.Entry.of("request-id", "abc")),
() -> {
log.warn(
"oh-no!",
Log.Entry.of("failed-for-id", 123)
);
}
)
}
);Looking past the lambdas, which are only taking so much visual budget because of the trivial-ness of the example, I am pretty happy with this API. The innermost log will have both the request-id and os-name available within its context as well as the failed-for-id directly in its entries component.
Crawling for all the log entries available in the entire linked list for a log is slightly non-trivial, so I think it would be beneficial for Log itself to implement Iterable\<Log> and do that crawling upon request.
A lot of the code so far has been ugly on the outside. I think this code is ugly on the inside too.
sealed interface Log extends Iterable<Log.Entry> {
// ...
@Override
default Iterator<Entry> iterator() {
return new Iterator<>() {
Iterator<Entry> iter = entries().iterator();
Context ctx = context();
@Override
public boolean hasNext() {
if (iter.hasNext()) {
return true;
} else {
if (ctx instanceof Context.Child.Plain plainCtx) {
iter = plainCtx.entries().iterator();
ctx = plainCtx.parent();
return this.hasNext();
} else if (ctx instanceof Context.Child.Span spanCtx) {
ctx = spanCtx.parent();
return this.hasNext();
} else if (ctx instanceof Context.Global globalCtx) {
iter = globalCtx.entries().iterator();
ctx = null;
return this.hasNext();
} else {
return false;
}
}
}
@Override
public Entry next() {
if (iter.hasNext()) {
return iter.next();
} else {
if (ctx instanceof Context.Child.Plain plainCtx) {
iter = plainCtx.entries().iterator();
ctx = plainCtx.parent();
return this.next();
} else if (ctx instanceof Context.Child.Span spanCtx) {
ctx = spanCtx.parent();
return this.next();
} else if (ctx instanceof Context.Global globalCtx) {
iter = globalCtx.entries().iterator();
ctx = null;
return this.next();
} else {
throw new NoSuchElementException();
}
}
}
};
}
}Now to have parity with SLF4J we should be able to delegate logging to a specific implementation on the class/module-path.
To do this, we first need to make an interface for creating loggers.
interface LoggerFactory {
Logger createLogger();
}And then we need to declare in our module-info.java that we are interested in consuming external implementors of this interface - just in case people ever decide to put this on the module-path.
import dev.mccue.log.alpha.LoggerFactory;
module dev.mccue.log.alpha {
exports dev.mccue.log.alpha;
uses LoggerFactory;
}Then we can build a factory function which scans through available implementations and picks one.
public interface LoggerFactory {
static LoggerFactory create() {
var loggerFactories = ServiceLoader.load(LoggerFactory.class).iterator();
if (!loggerFactories.hasNext()) {
System.err.println(
"No logger factory supplied. Falling back to no-op logger"
);
return () -> (__) -> {
};
} else {
var service = loggerFactories.next();
if (loggerFactories.hasNext()) {
var services = new ArrayList<LoggerFactory>();
services.add(service);
while (loggerFactories.hasNext()) {
services.add(loggerFactories.next());
}
System.err.printf(
"Multiple logger factories supplied: %s. Picking one at random.%n",
services
);
return services.get(ThreadLocalRandom.current().nextInt(0, services.size()));
} else {
return service;
}
}
}
Logger createLogger();
}The reason for the indirection - using a LoggerFactory instead of a Logger - is to allow for implementations to do some one-time set up logic and potentially set up logic per created logger.
In the context of Java, the namespace of a log would often be the name of the class that the log is in. This is why SLF4J has LoggerFactory.getLogger(Class<?>) as the obvious way to get a logger. Matching that convention is easy enough.
public interface LoggerFactory {
static LoggerFactory create() {
// ...
}
static Logger getLogger() {
return create().createLogger();
}
static Logger.Namespaced getLogger(String namespace) {
return getLogger().namespaced(namespace);
}
static Logger.Namespaced getLogger(Class<?> klass) {
return getLogger().namespaced(klass.getCanonicalName());
}
Logger createLogger();
}So now constructing a logger will look a lot like SLF4J
public final class Main {
private static final Logger.Namespaced log =
LoggerFactory.getLogger(Main.class);
public static void main(String[] args) {
log.info(
"item-delivered",
Log.Entry.of("cost", "everything")
);
}
}There will probably be an itch for some to generate the getLogger call like what lombok does for other loggers.
I can't add to lombok, I have a life, but I can generate the code with an annotation processor.
@DeriveLogger
public final class Main implements MainLog {
public static void main(String[] args) {
log.info(
"item-delivered",
Log.Entry.of("cost", "everything")
);
}
}// ~= to what is generated.
sealed interface MainLog permits Main {
Logger.Namespaced log =
LoggerFactory.getLogger(Main.class);
}As someone correctly pointed out to me, I never really clarified why any of this is "better".
The gist of it is that this API allows and enforces structured logging. That is, because there is a data-ified representation of events that happen within your system you can trivially transform them into structured formats such as JSON.
When your logs are all JSON you can use tools like Cloudwatch metric insights to directly search over your data.
fields @timestamp, @message
| sort @timestamp desc
| filter uri = '/something'
| limit 20The exact methodology for this will vary from service to service, but the overarching theme is that structured data is searchable. Text data is "grep-able".
Logically when you log something in a classical framework you take a representation in memory and turn it into some "English." Then when you inspect those logs you need to undo that transformation to English to do searching. Because its 2022 there is no chance you could search those logs by hand with any reasonable scale, so you have to fall back to taking the part of your log message that is a constant and searching for that.
So with structured logging, you can skip the english and ship data directly to your observability platforms. This is just a potential API for structured logging or, more accurately, what tracing calls "in process tracing"
Let me know if this explanation doesn't track in the comments.
Well, I am pretty confident that the API is good enough to start experimenting with. You can find the code for that here.
The annotation processor is also simple enough that I think it can be used right now. Code for that is here.
Both of those finished-ish components can be fetched from jitpack.
<repositories>
<repository>
<id>jitpack.io</id>
<url>https://jitpack.io</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>dev.mccue</groupId>
<artifactId>log.alpha</artifactId>
<version>main-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>dev.mccue</groupId>
<artifactId>log.alpha.generate</artifactId>
<version>main-SNAPSHOT</version>
</dependency>
</dependencies>Everything else - like my rough draft JSON logger, publisher system implementation, etc - currently live in these repos.
Contributions very welcome. Feel free to reach out to me directly on discord or similar.
A lot of design decisions I made were in support of a hypothetical system where µ/log's publisher scheme was translated. I wrote this up before finishing that prototype because I saw it would be a lot of work, and I didn't want to take the dive if there was no actual interest.
I have a sketch of what one could look like that turns SLF4J logs into records with slf4j/message, slf4j/arguments, and slf4j/mdc. This technically works in terms of information conveyance but isn't very pretty. I bet someone knows how to do better.
tracing proves that you can have structured logging and still pretty, developer friendly console logs. Everything I make is a Shrek so I probably need help to pull that off.
I didn't test any of this. If you can look me in the eye and say you would have written unit tests for all the log entry of functions I commend you. Some stuff might need to change to allow for unit testing applications which care about asserting that logs happen in the form they expect, but I haven't gone down that rabbit hole yet.
I went at this maybe a bit too much by feel. I have no clue about the performance of this API. Is getting the current thread every time an issue? Should I have added predicates to check if log levels are enabled? Make those hundreds of logger overloads? No clue. I should break out JMH or do some profiling.
If I said I didn't have the opportunity to write better docs that would be a lie. I spent that time watching Letterkenny. This whole thing probably counts as an explainer, but for there to be any chance of anyone using this the rest of Diátaxis could use some attention. In my head this would take the form of fleshed out reference Javadocs, a tutorial or two, and some how-to guides on managing a migration from SLF4J.
I need brave souls - whom I would love with all my heart, mind, and body - to try this API out in some real world applications. That is probably the only way to actually validate or invalidate any choices.
If nothing else, I hope this got some of you into the same nightmare head-space I'm trapped in. Leave unconstructive criticism in the comments below.